The Mythos of Visualization Literacy

…writing is inferior to speech. For it is like a picture, which can give no answer to a question, and has only a deceitful likeness of a living creature. It has no power of adaptation, but uses the same words for all. It is not a legitimate son of knowledge, but a bastard, and when an attack is made upon this bastard neither parent nor any one else is there to defend it.
—Socrates as recorded in Plato’s Phaedrus (trans. Benjamin Jowett, 1892)
In 2018 I wrote a blog post about how I was uncomfortable with the term “visualization literacy,” both because it felt like a poor metaphor for the various phenomena of interest but also because it felt like a way for designers to sort of shrug their shoulders and transfer the blame for failing to do enough work to make useful and explainable charts. It already felt like spitting in the wind then, and it feels even more pointless now that visualization literacy’s big brother, data literacy, has become a sort of catchall term for everything that is wrong with society. People believe silly things? Probably they just don’t have enough data literacy. People don’t know when something is real or fake? Not enough data literacy. Crops failing, livestock sick? Data literacy issue.
I’m being a bit glib, of course. There’s clearly something involved in data literacy beyond just a word to use to deflect blame. People I trust to know what they are doing are researching it, writing about it, measuring it, teaching it, consulting about it, etc. etc. In fact, that’s part of the problem: because “literacy” is just a metaphor here, and a rather diffuse one at that, there are almost too many things going on. And some the guises that data/visualization literacy can take on are less useful than others. It’s this notion of the multiplicity of literacies, and with the context of trying to get my head straight as part of my co-organizing duties for an upcoming visualization literacy workshop at CHI 2024, that I am essentially brain dumping the following approximately 4.5k words.
This post cribs its title and structure from Lipton’s “The Mythos of Model Interpretability”, one of my favorite recent(ish) papers that shows that a similar sort of vague concept — what it means for a machine learning model to be “interpretable” — is likewise both over- and under-defined (in that people have lots of very concrete definitions for the concept, but also that these definitions are very conceptually different and perhaps even contradictory). I’m applying Lipton’s model to visualization literacy for a similar rhetorical purpose: to challenge the notion that there is (or will be) a monolithic notion of what “visualization literacy” is, but that instead it’s a bunch of occasionally only tangentially related concepts in a trench coat.
Your immediate reaction might be something like “well, isn’t literacy just about ‘reading’ visualizations? What’s so complicated about that?” And lots of the current attempts to develop validated psychology scales (like the “VLAT” or the “Graph Literacy Scale”) for visualization literacy focus on this reading part. And yes, that’s part of it, but there’s reading and there’s reading, you know? To show what I mean, I’ll adapt an example from the Galesic and Garcia-Retamero paper on making a graph literacy scale I just linked to where they suggest a three-level model of reading, and add in a little bit from another one of my favorite papers by Lundgard and Satyanarayan where they assert a four-level model of graph semantics.

Let’s take, as my working example, this line chart of CIA world factbook data of worldwide reported internet usage that I whipped up.
Level 1 reading here might be just literally reading what’s in the chart. E.g., that the y-axis is labelled “Internet Usage”, the x-axis is labelled “Year”, that the title is “Worldwide Internet Usage”, that it extends from 2000–2012, etc. You might think that this is just about reading and there’s no visualization component to this kind of literacy, but you still, e.g., need to know what an x-axis is, what a y-axis is, maybe even know that Tableau weirdly puts x-axis labels on top and you have to futz around with duplicated dimensions in order to put things on the bottom like every other piece of charting software. But it’s still mostly about reading actual words and numbers.
Level 2 is where we get into decoding (this is, confusingly, Level 1 in the G&G-R graph literacy scale; I guess they’d put the title reading stuff up in a Level 0 or something). For instance, knowing that the internet usage in the year 2000 was slightly less than 10% but more than 5%, or that it was a little over 40% in 2012. I use the term “decoding” because that’s what you’re really being asked to do here: to know that e.g. the vertical distance of a mark along the y-axis corresponds to a particular value of internet usage, that you then sort of go along to the left of the graph and read off the closest label, etc. etc. More on this later, but it should be at least plausible that somebody who knew how to read English but had never seen a line chart in their life could get all of the Level 1 questions you threw at them correct but miss some important Level 2 questions. For proof, here’s an example that I think I must use in about a third of the things I write these days, including the last time I wrote a blog post on this subject, a line chart from the New York Daily Tribune showing the course of 1849 cholera epidemic, cribbed once again from Scott Klein:
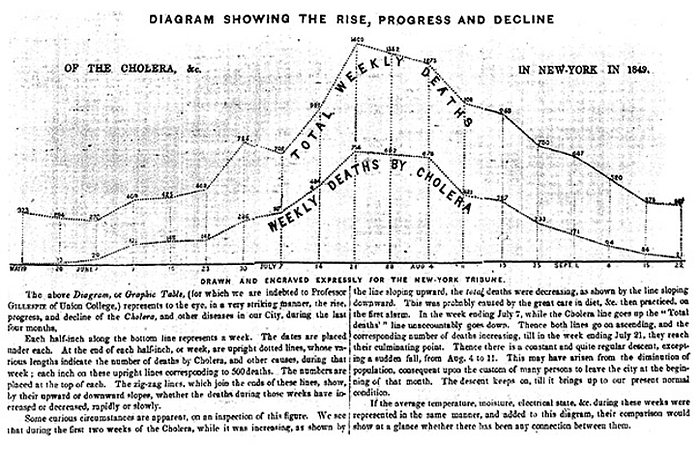
It’s a little fuzzy, but look at that caption! “Each half-inch along the bottom line represents a week. The dates are placed under each. At the end of each half-inch, or week…” and so on. The author wasn’t sure the readers would be familiar with the visual genre here, and so added explicit instructions on how to do Level 2-style explicit decoding, along with some commentary on what to take away, which is where we get into the higher levels of “reading.”
Returning to our original internet usage example, Levels 3 and 4 are where some of the more “interesting” stuff happens. For instance, to know “oh, hmm, it looks like internet usage is increasing at an approximately linear rate” or even “if the observed trend kept up, we’d expect over 50% of the world to use the internet by 2016 or so.” In other words, putting the pieces together to make statistical judgments, and, maybe, combining those judgments with knowledge about what the data represent, to make predictions or evaluate hypotheses or otherwise do purportedly insightful things in the domain of interest. Some of these things one would read from the chart are stochastic, in the same way that not everybody who reads a poem might get all of the allusions or references. But others seem more fundamental: for instance, we might expect people to know that line graphs are for showing trends, and so expect them to have good answers for trend-related questions, even if we aren’t expecting them to directly give us p-values or r² values or whatever in the same way that we’d expect them to directly give us the y-value for, say, the data point for the year 2008. But in any event this kind of literacy seems to involve more than just reading labels or knowing visual conventions, but also knowing a bit about statistics, a bit about the actual phenomena being measured, and perhaps even a little “epistemic luck” for more complex or detailed charts.
The keen-eyed reader will note some fuzziness slipping in. Some of the parts of this reading are procedural knowledge: knowing how to, e.g., go from the angles in a pie chart to an estimate of value. Some of it is declarative knowledge: knowing that, e.g., a treemap is meant to encode a part-to-whole relationship. Some of it is pulling things out of the chart (like decoding values), others are about what you put into the chart. For instance, I bet if I hadn’t titled the x-axis “Year” you’d still have assumed that the chart was showing temporal change over years, because you’ve seen a million other time series line charts like that, and know that 2000–2012 are plausible year ranges for these data in a way that, say, 1900–1912 or 3000–3012 wouldn’t have been. That kind of implicit knowledge is a type of literacy too!
I sort of implicitly presented these “levels of reading” as though they are a natural progression in either pedagogy or process, in that once you have reached the highest level you get all the ones below it en passant, but I don’t know if that’s true either. For instance, if you noticed the overall trend, I don’t think you explicitly decoded each individual data point as part of a Level 2 reading and then did some Level 3 math on them; I think you probably just visually estimated the trend and probably wouldn’t have consciously known what the y-value of a particular year was unless I asked you for it. There’s also some of this literacy stuff that belongs to the individual (your particular skills), and some that might belong to the society in which you are immersed: we’re in a society where we see line charts all the time but don’t see Western blot tests all the time, and so I was reasonable sure you’d know how to read the line chart, but I would have done a bit more hand-holding if I had used a more bizarre example (like a temporal treemap or something). And in English we read left to right instead of right to left, and so read time from left to right as well. And, hey, I assumed you were literate in English and sighted and so on: you could be plenty data literate by most measures and not have those things be true, and that’s on me, not you, if you fail to figure out what the chart was communicating on that basis.
The Desiderata of Visualization Literacy

So with, this fuzziness in mind, I’d like to ideate a little bit more about the other bits of visualization literacy that aren’t just the literal reading of values, title, and legends in a chart. I’m once again stealing from Lipton here with this subtitle, but I do want to point out how I have never in my life seen the word “desiderata” anywhere except for academic papers and yet it has been creeping into my writing in a way I find personally upsetting. If I start suggesting that we move “towards a hermeneutics” of something (and I almost have a few times), probably best to just put me out to pasture. But you get the idea: when we say that we want someone to be “graph literate” or “chart literate” or whatever, what are the qualities we are actually looking for? I think, generally, we mean a lot of things, mostly because all of our baggage from regular old “literacy” is coming along for the ride in this new context. Some of it is some of this multi-level reading stuff, but not all of it.
Following the Decoding Procedure
I used the word “decoding” above because visualization people, drawing on a long theoretical basis extending from Jacque Bertin’s Semiology of Graphics on down, really like to think of visualization as a process of decoding and encoding. You choose a visual variable to encode a particular aspect of the data, and then the process of reading it is just going back from visual property to value. So, e.g., you’d say that in my internet usage chart above, year is being encoded by horizontal position, internet usage by vertical position. I’ve talked a little bit in the past about why this particular framing has never sat well with me, but it is a really nice bit of cognitive technology to have. For one, it means that you’re not constrained by what Elijah Meeks calls “the taxonomy problem” where learning how to interpret a visualization means learning about each individual design category in a vacuum (for instance, a “learn charts” course would have to have day 1 be bar charts, day 2 be pie charts, day 3 be line charts, and so on until eventually you get to parallel coordinate plots or alluvial diagrams or whatever some time several years in the future). For another, it means that even super complicated visualizations like Giorgia Lupi’s “Data Items: A Fashion Landscape” are no sweat:
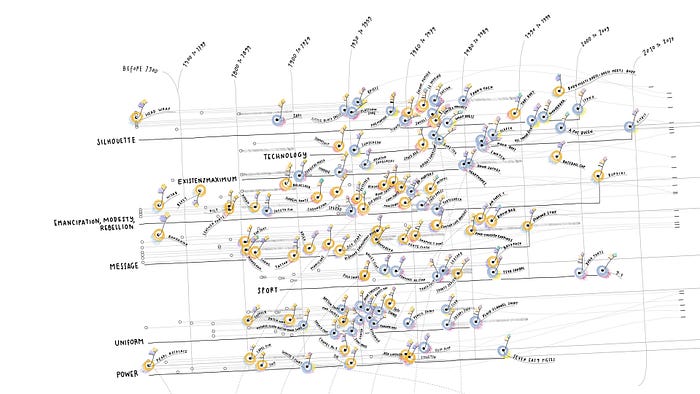
You’d see all this stuff, look over to the side for the legend:

And, patiently, go, “aha, this is a glyph-based chart, and different parts of the glyph are encoding goal, origin, type, etc.” even though you’d never seen anything precisely like it before, and are unlikely to see it replicated precisely on new data ever again. It would still take me a while to internalize and actually process all of the encodings, but I’m confident I’d eventually be able to manage it.
But decoding is not all there is to reading, for several reasons, but mainly because reading off specific values is not all that there is to visualization. For instance, this chart below, just like the cholera line chart I showed above, has a bunch of text telling you precisely how to read it:
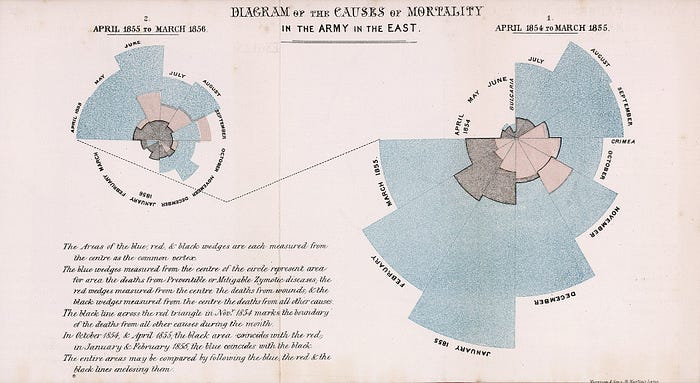
But can you tell me, for instance, precisely how many deaths there were in January 1855, broken out by different causes? No, you can’t, because there’s no numbers, because that’s not what this chart is for. You can probably estimate a ratio of relative deaths by different causes within and between months, but that’s what it would be, just an estimate. And you might screw it up because, as the caption mentions, value is actually encoded by area rather than radius, which would be the other reasonable encoding assumption to make. But even if you messed up the decoding, I still think you would probably read this chart “correctly”, or at least mostly correctly, if you got the insight “wow, the blue wedges are way bigger than the other wedges” and, hopefully, “wow, the wedges on the left hand side are generally much much smaller than the wedges on the right hand side.” You’d get extra marks if you then go from those visual patterns to the intended message of “hey, infectious diseases and other preventable deaths are an outsized portion of deaths in this war, and something happened in mid 1855 that made those deaths go way down.” That’s a lot more about visual vibes than precise decoding.
Recognizing the Canon
Well, really, the thing you probably took away from that chart is “hey, I know this one, that’s Nightingale’s coxcomb chart.” It, along with Snow’s cholera map, Playfair’s time series charts, Minard’s map of Napoleon’s invasion, etc. etc. are part of the standard canon of visualizations that you would almost certainly see in a data vis course or textbook. I think that knowing the standard canon might be a form of being visualization literate, in the same way that we might expect a person who is literate in English to at least have heard of Shakespeare or Austen or Chaucer or whoever.
Or, if you think that’s a bridge too far, we might expect people to at least recognize the standard idioms of data visualization, in the same way that we expect people to recognize slang or common idiomatic expressions in written language. For instance, here’s this pie chart that gets used in almost every single lecture or article about bad or misleading data visualization, which I have only ever been able to find at this resolution or lower because some unknown person took a picture on their camera phone at some point circa 2009 and then everybody just passed it around without attribution:
From a pure reading standpoint there’s nothing much wrong with it (the 3D makes it hard to estimate the radius of the pie slices, I guess, but there are big labels so who cares). If I ask you “what percentage of people back Romney?” you’d say “60%” and be correct. But it’s wrong because in the idiom of the pie chart, we expect the slices to represent a part-to-whole relationship and for stuff to add up to 100% (I should note that, as far as I know, the data here are correct: the issue is that this chart was smashing together some polls about favorability, and favorability is not mutually exclusive, so people could have had favorable impressions of all three candidates simultaneously). You can “read” the chart correctly, but there seems to be some component of chart literacy where we have to know something about the types of things we are supposed to be reading, idioms and visual metaphors and established chart types and all.
Not Being Fooled
The Fox News pie chart above is, not coincidentally, a nice segue to another aspect of visualization literacy, which is not being misled by confusing or intentionally manipulative visualizations. In keeping with the proposed scales I mentioned earlier, Ge and Kay propose the CALVI test that is explicitly meant to capture critical thinking in visualization which, in practice, usually entails not falling for the standard tricks in the deceptive visualization arsenal. For instance, in another entry in the genre of “somebody took a fuzzy picture and now we all have to live with it because it’s a canonical example”:
A presumably graph literate person is supposed to look at this chart, detect that it’s a bar chart, do all the level 1 and level 2 stuff of seeing that it’s about tax rates, and that tax rates would increase in 2013, but then there is supposed to be the additional step of going “wait, that y-axis doesn’t seem right, it starts at 34% and exaggerates the effect size” and then doing something internally in their head to “correct” things to if the axis had begun at the “proper” 0%:

The actual issue in this specific case turns out to be a little less straightforward, as we learned, but you get the idea. This kind of seeing that somebody might be messing with you seems to be at a “higher” level of reading than the 1–4 levels I laid out before: you have to see a statistical pattern, but know enough about the data and the visualization to doubt or even contradict the apparent pattern you just pulled out of the chart.
I think a lot of the stuff that makes people wave data and visualization literacy around like it’s a crucifix warding off a particularly scary vampire happens in this category. When people are misinformed or believe incorrect and/or scary things, it’s tempting to go, “ah, alas, they probably got fooled by some biased or misleading charts somewhere, if only we had gotten them a seat in my graduate class.” And I think that’s bullshit. At the practical level because I think the real misleading stuff happens at the level of selecting datasets and measurements and motivated reasoning and a whole host of other bad behaviors that do their damage long before you get to the particulars of chart design: “futzing with the y-axis” is an infinitesimal slice of that particular bag of dirty tricks. But also, as I’ve attempted to articulate elsewhere, the virtues that we ascribe to allegedly data literate people, around checking for sources and looking for biases and alternative explanations and so on, are precisely what the people we think have been “fooled” are already doing! If somebody’s issue is that they don’t believe authority figures, “hmmm, it’s probably because they weren’t skeptical enough” seems like a very silly “fix” to that problem.
If I’ve been peeved in the past with the prior definitions of literacy because they blame the viewer for the alleged crime of not understanding a poorly or confusingly made chart, I am likewise mad at applications of this particular definition that assume that authority figures don’t need to make arguments or persuade or try to convince people, or that the people who aren’t immediately persuaded or convinced are inherently deficient.
Creating New Utterances
Another subtle trick I’ve been playing throughout this article is to try to supplement exterior examples with visualizations I’ve created myself. This is for ethos-establishing reasons. Like, if I made my visualizations by poorly drawing them in MS Paint, or uploading pictures of me drawing them on butcher paper with crayons, then I probably would be undermining my credibility here. As an aside, I think there’s a relate ethos-establishing thing that scientists will do where they will make intentionally ugly or complex charts to prove that they “don’t care about all that fancy stuff” and “just want to show the data”, but that’s a story for another day. But I bring all of this up because creating charts seems to be an important part of literacy in the same way that writing, not just reading, is an important part of literacy in language.
This creation step doesn’t seem like too tall of an order. As stuff like the Dear Data project shows, you can create a data visualization just by recording the things that you see around you and breaking out some colored pencils and a few index cards. They won’t necessarily be very good data visualizations until you’ve worked up some chops around visual design, and they may not be very interesting data visualizations depending on what kind of life you lead, but it’s not like Where’s Spot? needed to be a page-turner to get the pedagogical job done. In fact, this sort of constructive-based learning might be a pretty important part of learning about charts in the first place. This kind of creation is certainly a skill (it’s probably several interlinked skills, actually) that can be different from all of the other types of literacy I’ve mentioned previously.
But I often think that when people associate visualization literacy with the act of creation, they are often specifically tying things to computational methods of creating visualization. In short, “can you make a visualization” is often a shorthand for talking about software packages “can you make a bar chart in Excel [or Tableau, or Illustrator, or…]”, or programming languages (“can you make a bar chart in python or javascript or R?”) or, and especially in corporate environments, specific libraries within those programming languages (“can you make a bar chart in matplotlib or d3 or ggplot?”). When we interviewed self-described non-experts working with data, it was in these precise terms that they discussed feeling guilty or left behind or inadequate: that they felt they should be using all of this “more advanced” tooling or coding, but were “stuck” using their normal procedures in their standard spreadsheet tools.
It’s in this meaning where I also get a little heated by how visualization literacy is often shunted off as a “problem” with specific people who just need to learn more. Computer science seems to be one of the few places where people make shitty tools and then blame the people trying to use them for not being smart enough to overcome poor design. If you want more people to be able to fluidly and fluently create useful visualizations well, then, get cracking on making better tools for that, don’t just sit there wringing your hands and telling people that they should have to get a CS degree. The fact that anybody on earth has to care about inherited syntax from S, python versioning and virtual environment systems, or javascript packaging options, are all signs of systematic and widespread failures of imagination somewhere, and I refuse to put up with it.
Speak the Prestige Dialect
“Literate” is often a synonym for “well-educated” which in turn is often a synonym for “aligned with the upper class.” I mean, here’s Professor ‘Enry ‘Iggins putting things directly:
I don’t know exactly what the data visualization equivalent of Received Pronunciation is, or what the equivalent of Audrey Hepburn selling flowers with an extremely artificial cockney accent is, but I have some ideas. There’s a genteel way of “speaking” data visualization, and part of assumed literacy is being able to code-switch into this register. When people say to “avoid pie charts,” for instance, it’s probably sometimes because they think there are better design alternatives out there, but I think a lot of it is part of fitting in with the in-crowd, who of course would not do something as gauche as to use a pie chart (here’s Robert Kosara and Jon Schwabish debating this point for 45 minutes, if you would like some more pie chart apologia). Specific statistical methods, charting libraries, or data formats similarly go in and out of fashion, and part of keeping up with the Joneses is fitting in with these trends.
The downsides to this version of literacy, beyond the sheer arbitrariness of some of these choices, is that, as with other forms of prestige, it isn’t evenly distributed in society. Big powerful organizations can collect and store lots of data, pay data scientists and designers and so on to make those data look pretty, whereas the people on the outside of those organizations are often left with vernacular forms of data-based expression. Just like a language is “a dialect with an army and a navy,” the ways that people that aren’t part of companies or research labs with databases or server farms laying around use or reason about data visually often get short shrift in our research, tooling, or rhetoric. But I think these “vernacular” or “folk” data practices are worth actually looking into. I mean, I’m probably not going to be spending several hundred thousand bucks to train a large language model from scratch, but I am definitely going to end up having to mess around in Excel at some point in the near future, so it’s wild to me that so much “data science” hype and research and capital is dedicated to studying the former instead of the latter.
Wrap Up
One of my favorite books is The Pillow Book, attributed to Sei Shōnagon. The book is a collection of reflections on palace life during Japan’s Heian era. Much of the drama of the book (diary? novel? epistle?) revolves around poetry. People will compose poems at each other as a way of flirting, go into weeks-long funks because they didn’t think the poems they composed were good enough, speak in poetic allusions, and then make fun of people for not getting those allusions. This is particularly funny because we, as the reader, don’t get those allusions either. Some of the poems that every respectable person would be ashamed not to know 900ish years ago survived, but many of them didn’t, and the footnotes in my translation will often mention “this is an allusion to a poem by XYZ, but it has been lost to history.” I think The Pillow Book shows just how temporally and societally constrained “literacy” is as a concept. The kind of writing and reading we do is just inherently intermixed with the kind of cultures in which we live. It’s not a single skill that an individual possesses, but an entire learned relationship with a society. I’ve gone this far without bringing Latour into things so I won’t start now, but I really do think that it’s this situatedness within a network that is central to data literacy generally, and chart literacy specifically.
If we’re in “visualization literacy is a relationship between an individual and a community” mode, then the following challenges to the usual conceptions of visualization literacy just fall out naturally. For example:
- Visualization literacy is not a single skill. It’s a collection of various capacities and strategies. Some of these components might be interconnected or related pedagogical dependencies, but others might not be. For instance, somebody could be very very good at creating very nice looking charts in d3 or something, but still fall prey to relatively elementary errors in reasoning or statistical interpretation. And if visualization literacy is not a single skill, it’s certainly not a binary skill either (you’re literate or you’re not): there are many possible gradations.
- Visualization literacy is not purely an individual skill, but a community skill. What it might mean to be visualization literate might depend on with whom you are “talking” about data. Idioms, assumptions, and rhetoric will differ from context to context. This also means that measuring a person’s visualization literacy in the same way we’d measure IQ might be misguided, and for similar reasons: literacy for whom and by whose standards?
- Visualization literacy is not a panacea. People can have all kinds of literacies and still be mistaken, misled, or stubborn. Even people that might ordinarily “know better” can be tired or inattentive or incurious. Correctly interpreting a parallel coordinate plot or something doesn’t automatically make you a good person, citizen, or scientist. It probably doesn’t hurt, though. Rather than using a call for visualization literacy as a tool to “fix” people, I would instead look at the problem from the opposite direction: what sort of barriers (or access, or comprehensibility) are we as designers putting in front of our audiences, and are these barriers appropriate? If not, what can we do to lower these barriers?